Introdução ao Kubernetes
22/06/2016Introdução
Kubernetes é uma plataforma open-source que tem como objetivo automatizar a implantação de aplicações orquestrando containers em um ambiente de cluster, fornecendo as melhores formas de gestão e componentes distribuídos como por exemplo: balanceamento de carga, redundância e gestão de configurações.
Inicialmente foi um projeto criado pelo Google com base em dois sistemas: Omega e Borg, adicionando as melhores práticas relacionadas a containers e clusters que o Google desenvolveu nos últimos dez anos. O projeto foi lançado como opensource em 2014 e atualmente é mantido por uma comunidade grande e recebe atualizações frequentes.
Arquitetura
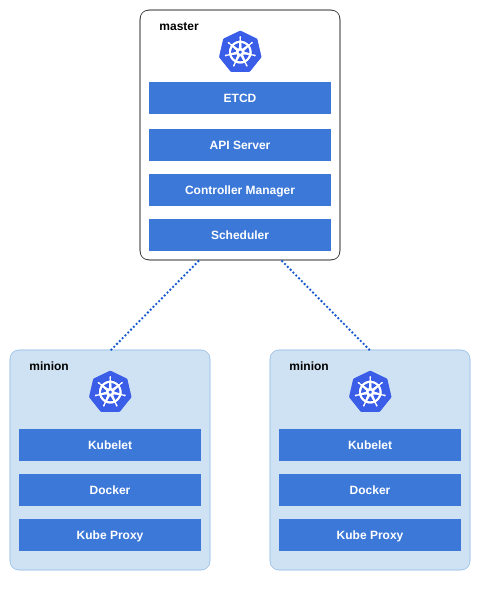
A ferramenta possui alguns conceitos e nomenclaturas diferentes, sua arquitetura é elaborada para ser altamente escalável. Kubernetes possui uma unidade de controle chamada de master server que executa vários serviços de uso exclusivo para o funcionamento do cluster.
Toda a comunicação e configuração do cluster é realizada por meio do ETCD um armazenamento de chave-valor (criado pelo CoreOS, lembra dele?) que salva o estado do cluster e compartilha entre os nós por meio de sua API HTTP/JSON.
O master server executa três componentes essenciais:
- APIServer para gestão de controle e agendamento de tarefas, basicamente ele recebe as solicitações e armazena no ETCD.
- Controller manager é responsável por garantir o estado atual do cluster, salvando as configurações que definem o tamanho e replicação no ETCD.
- Scheduler tem a tarefa de distribuir os containers que são chamados de pods em todo o cluster, os nós do cluster recebem a nomenclatura de minions.
Em cada minion temos um daemon do Docker em execução, além disso uma sub-rede privada dedicada à comunicação. Por meio da sub-rede temos rotas de tráfego para garantir o acesso a internet em todos os minions.
Temos ainda dois serviços que por padrão são executados em cada nó do cluster, kubelet que recebe as instruções enviadas do master e incializa ou encerra os containers. E temos o kube-proxy que é um proxy que permite o acesso externo ao cluster e realiza as rotas de tráfego para os containers.
Unidades de Trabalho
Existem três unidades básicas de trabalho que precisamos conhecer para implantar qualquer serviço com Kubernetes, são eles: Pod, ReplicationController e o Service. Essas unidades nada mais são que receitas que podem ser escritas em YAML(que lembram bastante um docker-compose.yml) ou JSON e servem para descrever como queremos construir os containers.
Pods
Um pod representa um ou mais containers que podem ser controlados como single application, ou seja geralmente são implantados como uma única aplicação, geralmente são containers que executam tarefas auxiliares mas que tem uma forte ligação com à aplicação principal.
Como exemplo, imagine um container que executa tarefas agendadas na aplicação:
apiVersion: v1
kind: Pod
id: crontab
metadata:
name: crontab
labels:
name: crontab
app: cron
spec:
version: v1
name: crontab
containers:
- name: crontab
image: crontab:latest
imagePullPolicy: Always
Esse pod poderia ser criado na linha de comando por meio do Kubernets client, o comando kubectl:
$ kubectl create -f crontab-pod.yaml
Replication Controller
O ReplicationController é uma outra forma de criar pods que podem ser escalados horizontalmente, em sua receita descrevemos a quantidade de cópias do pod que sempre devem existir no cluster, ou seja se por algum motivo um container falhar um outro container poderá ser iniciado e assumir o seu lugar mantendo o serviço sempre em execução.
Imagine que sua aplicação precisa ficar online com um número mínimo de containers para garantir disponibilidade, a receita de replication controller poderia ser assim:
apiVersion: v1
kind: ReplicationController
metadata:
name: website
spec:
replicas: 4
selector:
name: app
template:
metadata:
labels:
name: app
spec:
containers:
- name: website
image: website:v1
imagePullPolicy: Always
Diferente da receita inicial de single pod, aqui podemos notar a mudança em dois campos: Kind que agora especifica
o tipo ReplicationController e replicas que informa a quantidade de containers que será criado, neste caso 4.
Novamente para executar nossa receita usamos o kubectl:
$ kubectl create -f app-rc.yaml
Services
O Kubernetes trata o termo service como algo muito específico quando descrevemos uma receita deste tipo. Uma receita de service como o próprio nome diz, cria um serviço que funciona como um balanceador de carga básico para um grupo de containers. Por exemplo, todos os containers de backend criados por meio da receita de ReplicationController necessitam de um ponto único de acesso e é justamente isso que a receita de service pode proporcionar:
apiVersion: v1
kind: Service
id: nginx
metadata:
name: nginx
spec:
ports:
- port: 80
targetPort: 3000
publicIPs: ["xxx.xxx.xxx.xxx"]
selector:
name: app
Note que Kind agora recebe Service como valor e nas especificações dos serviços temos: port que informa a porta no qual o serviço deve responder, neste caso 80. Para o serviço se comunicar com os containers da aplicação é informado em targetPort a porta onde a aplicação de backend está respondendo, temos também o campo publicIPs onde podemos informar o ip público para acessar essa a aplicação e por fim o campo selector que realiza a associação com o grupo de containers que foram criados para a aplicação.
Para criar o service, mais uma vez podemos utilizar o kubectl:
$ kubectl create -f nginx-service.yaml
Dependendo do cloud escolhido para usar o Kubernetes, um load balancer será criado na plataforma.
Demonstração
Para compreendermos o potencial do Kubernetes em ambientes de produção, nesta seção veremos como criar um cluster no Google Container Engine. Escolhi o GKE para exemplo pois esta plataforma suporta Kubernetes por padrão e todos os recursos que ele apresenta.
Setup
Antes de iniciar o setup é necessário criar uma conta no Google Cloud Platform
e configurar o gcloud um cliente de acesso a plataforma do Google que pode
ser instalado por meio do Google Cloud SDK.
Com a conta criada e o gcloud instalado, podemos começar configurando o acesso a plataforma:
$ gcloud init
Your current configuration has been set to: [default]
To continue, you must log in. Would you like to log in (Y/n)? Y
Go to the following link in your browser:
https://accounts.google.com/o/oauth2/auth?redirect_uri=...
...
Por meio da url retornada no gcloud init é possível autenticar a sua conta google para começar a trabalhar com a plataforma.
O passo seguinte é para especificar a zona no Google Compute Engine.
Depois de configurado podemos obter informações do projeto existente ou criar um novo:
$ gcloud config list project
Your active configuration is: [default]
[core]
project = infoslack-1322
Neste caso irei utilizar o projeto infoslack-1322 existente, agora só precisamos do kubernetes:
$ wget -c https://storage.googleapis.com/kubernetes-release/release/v1.2.4/kubernetes.tar.gz
$ tar zxvf kubernetes.tar.gz
Iniciando o cluster
Agora que temos todos os pré-requisitos atendidos, podemos finalmente criar o cluster.
Antes de iniciar é necessário definir o provider que será utilizado pelo Kubernetes que por padrão
é setado para KUBERNETES_PROVIDER=gce ou seja Google Compute Engine, neste exemplo usaremos um diferente:
KUBERNETES_PROVIDER=gke ou Google Container Engine, outra variável obrigatória é a que define o nome do cluster CLUSTER_NAME
para iniciar o cluster só precisamos definir as variáveis de ambiente e executar o script de inicialização:
$ export KUBERNETES_PROVIDER=gke
$ export CLUSTER_NAME=rails-demo-gke
$ cluster/kube-up.sh
Durante o processo de criação do cluster é solicitado a instalação de componentes para o gcloud, confirme e prossiga a instalação.
Ao final recebemos a informação que o cluster foi criado com sucesso e está pronto para ser usado:
Cluster validation succeeded
Done, listing cluster services:
Kubernetes master is running at https://104.197.169.204
GLBCDefaultBackend is running at https://104.197.169.204/api/v1/proxy/namespaces/kube-system/services/default-http-backend
Heapster is running at https://104.197.169.204/api/v1/proxy/namespaces/kube-system/services/heapster
KubeDNS is running at https://104.197.169.204/api/v1/proxy/namespaces/kube-system/services/kube-dns
kubernetes-dashboard is running at https://104.197.169.204/api/v1/proxy/namespaces/kube-system/services/kubernetes-dashboard
No dashboard do Google Cloud Platform é possível ver mais de talhes sobre o cluster que foi criado:
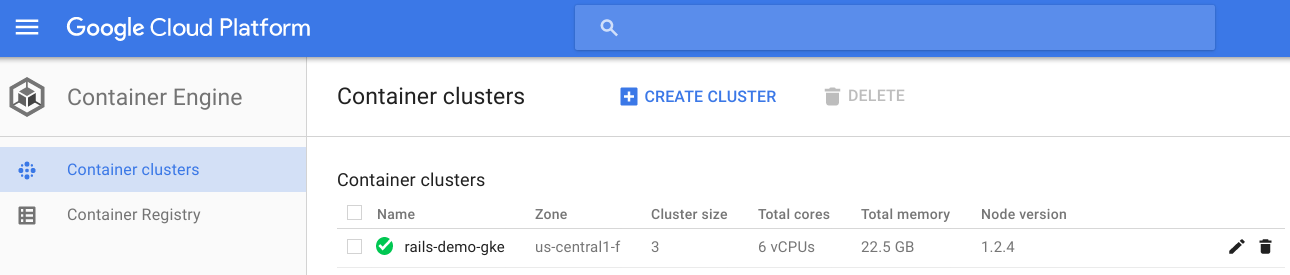
Você também pode utilizar a linha de comando com o utilitário kubectl e obter informações sobre o cluster:
$ kubectl get nodes
NAME STATUS AGE
gke-rails-demo-gke-default-pool-dc420d70-k28q Ready 7m
gke-rails-demo-gke-default-pool-dc420d70-ujvw Ready 7m
gke-rails-demo-gke-default-pool-dc420d70-uvnr Ready 7m
Deploy de uma aplicação Rails
Com o cluster pronto podemos realizar o deploy de uma aplicação e ver como tudo funciona. Neste exemplo irei utilizar uma aplicação Rails configurada para executar no ambiente de produção, o exemplo que será utilizado está disponível no github.
Antes de começar irei configurar uma instância para banco de dados pois não quero utilizar um container para isso, afinal estamos simulando produção ;)
O Google fornece receitas automatizadas de provisionamento chamado de Cloud Launcher e é justamente por meio dele que estou provisionando a instância de PostgreSQL, ao final do provisionamento recebemos os dados necessários para que à aplicação possa utilizar:
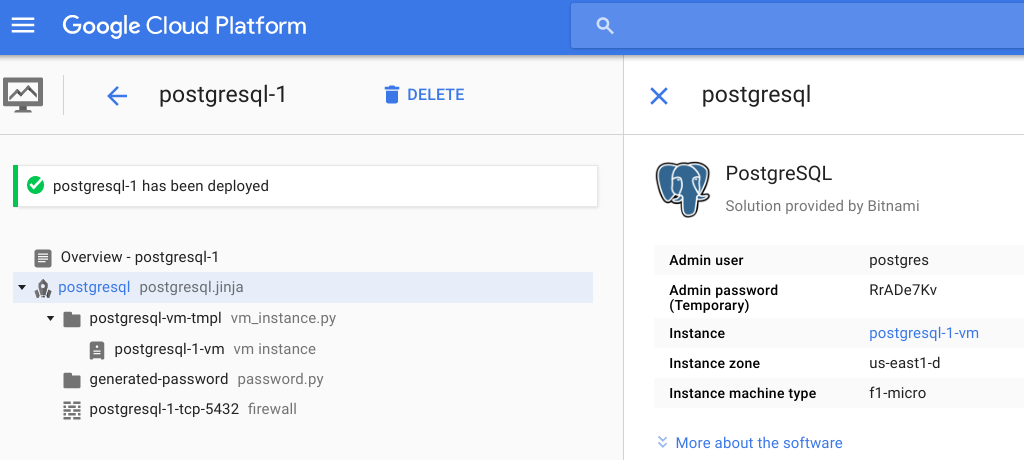
Bem, agora podemos dar uma olhada na receita de ReplicationController que será utilizada para deploy da aplicação:
apiVersion: v1
kind: ReplicationController
metadata:
labels:
name: app
name: k8s-rails-demo
spec:
replicas: 4
selector:
name: app
template:
metadata:
labels:
name: app
spec:
containers:
- image: infoslack/k8s-demo:latest
name: app
ports:
- containerPort: 4000
name: http-server
env:
- name: "DATABASE_URL"
value: "postgres://postgres:RrADe7Kv@10.142.0.3:5432/dbprod"
- name: "SECRET_KEY_BASE"
value: "8cc599caea1ec2acc58029257297cf9bfc3af60a"
command: ["passenger", "start", "-p", "4000", "-e", "production"]
Note o tipo definido kind: ReplicationController com um total de 4 réplicas
ou seja sempre teremos 4 containers da aplicação funcionando.
Em image a receita diz ao kubernetes para que faça docker pull no cluster,
em cada nó que for escolhido para ser utilizado.
Além disso temos as definições de variáveis de ambiente para acessar o banco
de dados e outra muito importânte para o Rails. Por fim temos a instrução
command que inicializa a aplicação na porta 4000.
Por meio do comando kubectl podemos fazer o deploy da aplicação no cluster:
$ kubectl create -f app-rc.yml
replicationcontroller "k8s-rails-demo" created
Ainda via kubectl é possível ver o status dos containers no cluster:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
k8s-rails-demo-bmke7 1/1 Running 0 48s
k8s-rails-demo-chzrh 1/1 Running 0 48s
k8s-rails-demo-spey6 1/1 Running 0 48s
k8s-rails-demo-vs2wu 1/1 Running 0 48s
Também é possível acessar qualquer um dos containers de aplicação:
$ kubectl exec -it k8s-rails-demo-bmke7 bash
root@k8s-rails-demo-bmke7:/app#
Para obter mais detalhes também podemos utilizar o dashboard do Kubernetes,
ele é configurado na instância master do cluster e necessita de autenticação,
podemos obter os dados necessários por meio da instrução kubectl config view:
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: REDACTED
server: https://104.197.169.204
name: gke_infoslack-1322_us-central1-f_rails-demo-gke
contexts:
- context:
cluster: gke_infoslack-1322_us-central1-f_rails-demo-gke
user: gke_infoslack-1322_us-central1-f_rails-demo-gke
name: gke_infoslack-1322_us-central1-f_rails-demo-gke
current-context: gke_infoslack-1322_us-central1-f_rails-demo-gke
kind: Config
preferences: {}
users:
- name: gke_infoslack-1322_us-central1-f_rails-demo-gke
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
password: LG0Ja8j71VoBOGfT
username: admin
Acessando o endereço ip https://104.197.169.204/ui e realizando a autenticação podemos navegar no dashboard:
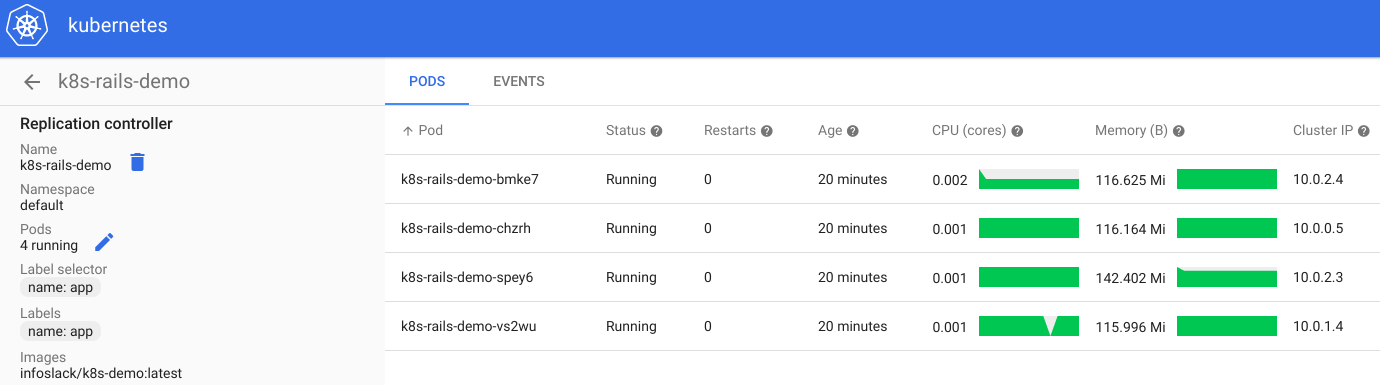
Temos a aplicação funcionando mas ainda não à acessamos, para acessar rápidamente poderíamos liberar no firewall a porta 4000 para cada nó do cluster e escolher um dos ips para acessar. Faremos algo mais elegante, adicionaremos um load balancer que verifica a porta 4000 de cada container e redireciona para porta 80:
apiVersion: v1
kind: Service
metadata:
name: app
labels:
name: app
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 4000
protocol: TCP
selector:
name: app
A receita cria um service que funciona como LoadBalancer, basicamente um balancer é criado na infra do Google e recebe um ip fixo:
$ kubectl create -f app-service.yml
service "app" created
Agora basta verificar se o balancer foi criado:
kubectl get services
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
app 10.3.253.200 104.197.240.45 80/TCP 5m
kubernetes 10.3.240.1 <none> 443/TCP 1d
Temos um ip externo que atende na porta 80, agora podemos ver a aplicação funcionando:
Finalizando o cluster
Você pode destruir o cluster rapidamente por meio do script kube-down.sh:
$ cluster/kube-down.sh
Bringing down cluster using provider: gke
... in gke:verify-prereqs()
All components are up to date.
All components are up to date.
All components are up to date.
All components are up to date.
... in gke:kube-down()
... in gke:detect-project()
Your active configuration is: [default]
... Using project: infoslack-1322
Deleting cluster rails-demo-gke...done.
Deleted [https://container.googleapis.com/v1/projects/infoslack-1322/zones/us-central1-f/clusters/rails-demo-gke].
Done
Todo o cluster será excluído. Se você está seguindo o exemplo e descartou o cluster não esqueça de remover a instância do PostgreSQL para não ficar gerando despesas na sua conta.
Conclusão
O Kubernetes é uma plataforma de orquestração robusta e de configurações flexíveis, estou gostando do seu funcionamento no ambiente de produção. Em outros posts abordarei mais detalhes sobre estratégias de deploy, configurações de secrets e isolamento por namesapces com exemplos na AWS.
Se você estiver curioso e quiser reproduzir o exemplo visto na plataforma do Google, eles estão liberando um crédito de $300 válidos por 60 dias: https://cloud.google.com/free-trial/
Happy Hacking ;)
Referências
- http://kubernetes.io/
- http://kubernetes.io/docs/user-guide/walkthrough/
- http://kubernetes.io/docs/user-guide/walkthrough/k8s201/
- http://research.google.com/pubs/pub41684.html
- http://research.google.com/pubs/pub43438.html
- https://cloud.google.com/container-engine/
- https://github.com/infoslack/k8s-demo